UPDATE: See the packets and find out if you're affected here.
UPDATE 2: Yes, I've reproduced this issue regardless of OS, ASPM state/settings, or software firewall settings. Obviously if you have a layer 2/3 firewall in front of an affected interface you'll be ok.
Packets of death. I started calling them that because that’s exactly what they are.
Star2Star has a hardware OEM that has built the last two versions of our on-premise customer appliance. I’ll get more into this appliance and the magic it provides in another post. For now let’s focus on these killer packets.
About a year ago we released a refresh of this on-premise equipment. It started off simple enough, pretty much just standard Moore’s Law stuff. Bigger, better, faster, cheaper. The new hardware was 64-bit capable, had 8X as much RAM, could accommodate additional local storage, and had four Intel (my preferred ethernet controller vendor) gigabit ethernet ports. We had (and have) all kinds of ideas for these four ports. All in all it was pretty exciting.
This new hardware flew through performance and functionality testing. The speed was there and the reliability was there. Perfect. After this extensive testing we slowly rolled the hardware out to a few beta sites. Sure enough, problems started to appear.
All it takes is a quick Google search to see that the Intel 82574L ethernet controller has had at least a few problems. Including, but not necessarily limited to, EEPROM issues, ASPM bugs, MSI-X quirks, etc. We spent several months dealing with each and every one of these. We thought we were done.
We weren’t. It was only going to get worse.
I thought I had the perfect software image (and BIOS) developed and deployed. However, that’s not what the field was telling us. Units kept failing. Sometimes a reboot would bring the unit back, usually it wouldn’t. When the unit was shipped back, however, it would work when tested.
Wow. Things just got weird.
The weirdness continued and I finally got to the point where I had to roll my sleeves up. I was lucky enough to find a very patient and helpful reseller in the field to stay on the phone with me for three hours while I collected data. This customer location, for some reason or another, could predictably bring down the ethernet controller with voice traffic on their network.
Let me elaborate on that for a second. When I say “bring down” an ethernet controller I mean BRING DOWN an ethernet controller. The system and ethernet interfaces would appear fine and then after a random amount of traffic the interface would report a hardware error (lost communication with PHY) and lose link. Literally the link lights on the switch and interface would go out. It was dead.
Nothing but a power cycle would bring it back. Attempting to reload the kernel module or reboot the machine would result in a PCI scan error. The interface was dead until the machine was physically powered down and powered back on. In many cases, for our customers, this meant a truck roll.
While debugging with this very patient reseller I started stopping the packet captures as soon as the interface dropped. Eventually I caught on to a pattern: the last packet out of the interface was always a 100 Trying provisional response, and it was always a specific length. Not only that, I ended up tracing this (Asterisk) response to a specific phone manufacturer’s INVITE.
I got off the phone with the reseller, grabbed some guys and presented my evidence. Even though it was late in the afternoon on a Friday, everyone did their part to scramble and put together a test configuration with our new hardware and phones from this manufacturer.
We sat there, in a conference room, and dialed as fast as our fingers could. Eventually we found that we could duplicate the issue! Not on every call, and not on every device, but every once in a while we could crash the ethernet controller. However, every once in a while we couldn’t at all. After a power cycle we’d try again and hit it. Either way, as anyone who’s tried to diagnose a technical issue knows the first step is duplicating the problem. We were finally there.
Believe me, it took a long time to get here. I know how the OSI stack works. I know how software is segmented. I know that the contents of a SIP packet shouldn’t do anything to an ethernet adapter. It just doesn’t make any sense.
Between packet captures on our device and packet captures from the mirror port on the switch we were finally able to isolate the problem packet. Turns out it was the received INVITE, not the transmitted 100 Trying! The mirror port capture never saw the 100 Trying hit the wire.
Now we needed to look at this INVITE. Maybe the userspace daemon processing the INVITE was the problem? Maybe it was the transmitted 100 Trying? One of my colleagues suggested we shutdown the SIP software and see if the issue persisted. No SIP software running, no transmitted 100 Trying.
First we needed a better way to transmit the problem packet. We isolated the INVITE transmitted from the phone and used tcpreplay to play it back on command. Sure enough it worked. Now, for the first time in months, we could shut down these ports on command with a single packet. This was significant progress and it was time to go home, which really meant it was time to set this up in the lab at home!
Before I go any further I need to give another shout out to an excellent open source piece of software I found. Ostinato turns you into a packet ninja. There’s literally no limit to what you can do with it. Without Ostinato I could have never gotten beyond this point.
With my packet Swiss army knife in hand I started poking and prodding. What I found was shocking.
It all starts with a strange SIP/SDP quirk. Take a look at this SDP:
v=0
o=- 20047 20047 IN IP4 10.41.22.248
s=SDP data
c=IN IP4 10.41.22.248
t=0 0
m=audio 11786 RTP/AVP 18 0 18 9 9 101
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:0 PCMU/8000
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:9 G722/8000
a=rtpmap:9 G722/8000
a=fmtp:101 0-15
a=rtpmap:101 telephone-event/8000
a=ptime:20
a=sendrecv
Wireshark picture:
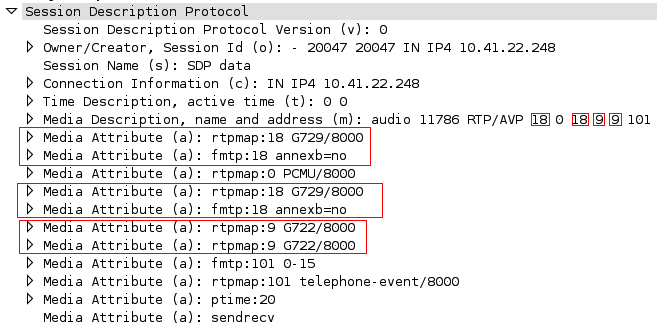
Yes, I saw it right away too. The audio offer is duplicated and that’s a problem but again, what difference should that make to an Ethernet controller?!? Well, if nothing else it makes the ethernet frame larger...
But wait, there were plenty of successful ethernet frames in these packet captures. Some of them were smaller, some were larger. No problems with them. It was time to dig into the problem packet. After some more Ostinato-fu and plenty of power cycles I was able to isolate the problem pattern (with a problem frame).
Warning: we’re about to get into some hex.
The interface shutdown is triggered by a specific byte value at a specific offset. In this case the specific value was hex 32 at 0x47f. Hex 32 is an ASCII 2. Guess where the 2 was coming from?
a=ptime:20
All of our SDPs were identical (including ptime, obviously). All of the source and destination URIs were identical. The only difference was the Call-IDs, tags, and branches. Problem packets had just the right Call-ID, tags, and branches to cause the “2” in the ptime to line up with 0x47f.
BOOM! With the right Call-IDs, tags, and branches (or any random garbage) a “good packet” could turn into a “killer packet” as long as that ptime line ended up at the right address. Things just got weirder.
While generating packets I experimented with various hex values. As if this problem couldn’t get any weirder, it does. I found out that the behavior of the controller depended completely on the value of this specific address in the first received packet to match that address. It broke down to something like this:
Byte 0x47f = 31 HEX (1 ASCII) - No effect
Byte 0x47f = 32 HEX (2 ASCII) - Interface shutdown
Byte 0x47f = 33 HEX (3 ASCII) - Interface shutdown
Byte 0x47f = 34 HEX (4 ASCII) - Interface inoculation
Bad:

Good:

When I say “no effect” I mean it didn’t kill the interface but it didn’t inoculate the interface either (more on that later). When I say the interface shutdown, well, remember my description of this issue - the interface went down. Hard.
With even more testing I discovered this issue with every version of Linux I could find, FreeBSD, and even when the machine was powered up complaining about missing boot media! It’s in the hardware; the OS has nothing to do with it. Wow.
To make matters worse, using Ostinato I was able to craft various versions of this packet - an HTTP POST, ICMP echo-request, etc. Pretty much whatever I wanted. With a modified HTTP server configured to generate the data at byte value (based on headers, host, etc) you could easily configure an HTTP 200 response to contain the packet of death - and kill client machines behind firewalls!
I know I’ve been pointing out how weird this whole issue is. The inoculation part is by far the strangest. It turns out that if the first packet received contains any value (that I can find) other than 1, 2, or 3 the interface becomes immune from any death packets (where the value is 2 or 3). Also, valid ptime attributes are defined in
All of a sudden it’s become clear why this issue was so sporadic. I’m amazed I tracked it down at all. I’ve been working with networks for over 15 years and I’ve never seen anything like this. I doubt I’ll ever see anything like it again. At least I hope I don’t...
I was able to get in touch with two engineers at Intel and send them a demo unit to reproduce the issue. After working with them for a couple of weeks they determined there was an issue with the EEPROM on our 82574L controllers.
They were able to provide new EEPROM and a tool to write it out. Unfortunately we weren’t able to distribute this tool and it required unloading and reloading the e1000e kernel module, so it wouldn’t be preferred in our environment. Fortunately (with a little knowledge of the EEPROM layout) I was able to work up some bash scripting and ethtool magic to save the “fixed” eeprom values and write them out on affected systems. We now have a way to detect and fix these problematic units in the field. We’ve communicated with our vendor to make sure this fix is applied to units before they are shipped to us. What isn’t clear, however, is just how many other affected Intel ethernet controllers are out there.
I guess we’ll just have to see...
105 comments:
"I was able to work up some bash scripting and ethtool magic to save the “fixed” eeprom values and write them out on affected systems. "
Do you mind sharing?
I'm sure I'll get flamed for this, but this in my opinion is a direct result of outsourcing the design jobs to the Guadalajara Design Center. Having worked on the Patsburg chipset and Rosecity motherboard I can say with certainty this isn't the only product with problems in power management (aspm). The patsburg had a very serious issue with aspm during development and I don't believe a reliable fix was ever found. Registers were coming back from PM with the wrong values and they couldn't figure out what was causing it. It came down to the wire and I dont think it was fixed. Seeing what sounds like the same design and testing issues with this NIC doesn't surprise me know what I do about Intel and how it's run now.
You should make a site to test this bug with. I think an appropriate button name would be "PRAY!".
Terrific stuff btw, congrats on finding it.
I've updated the post with a link to different versions of the packet and instructions on how to use them.
Unfortunately I'm reluctant to share the EEPROM fix. Without knowing the exact meaning and purpose of the modified EEPROM values providing a tool to modify them seems a bit irresponsible. At this point I'm trying to determine how widespread the issue is. You can use the instructions I've now provided to find out if you're affected.
Maybe this is what someone had stumbled on earlier last year?
http://sourceforge.net/p/e1000/bugs/119/?page=3
If I read it well, you are basically saying that a simple `ping -p 32 -s 1110 x.x.x.x` can reliably take down most production farm.
I'm scared to see this persistent DoS weaponized, and I hope Intel is already pushing for upgrades.
This isn't the first time Intel cards have had to be modified in order to work properly:
http://sourceforge.net/projects/e1000/files/e1000e%20stable/eeprom_fix_82574_or_82583/
If you're only flipping a bit or two, you're probably disabling some hardware feature (probably a power management feature), as the link above does.
You mentioned that you're aware of the ASPM problem with that chip, and that the problem occurs even with no OS. Do you know if the problem occurs when an OS has booted up and disabled ASPM, such as with Linux and the boot arg "pcie_aspm=off"?
Luca - The packet is more complex than that and Intel has been aware of this issue for several months. They also have a fix. However, they haven't publicized it because they don't know how widespread it is.
Gordon - I'm aware of that issue and that fix. In this case the controller would reset regardless of OS, any OS settings, or any BIOS settings. ASPM appears to have nothing to do with it. In one of my tests I could reset the controller while the machine was hung at "Insert boot media".
most of the problems people have with the 82574L controller are usually assoicated with the EEPROM being mis-programmed just as you found. I've shipped probably a hundred thousand of these parts, and the only time there were issues was when the EEPROM was bad.
It basically reminded me about: https://bugzilla.kernel.org/show_bug.cgi?id=47331 but I guess it is unrelated.
Well, nobody can tell what the bits are in the eeprom until you tell us what bits are being flipped. (I'm not saying I'd know what they are either, but I'm sure the internet could sort it out.)
PS: I like your SIP INVITE in an ICMP packet.
"Weaponized"
This one is scary. There are so many hard systems out there that run infrastructure and rely on their computers to run properly.. If you think about it, we used to bomb infrastructure to take down communications, but with things like this, it's much cheaper.
Do these systems have IPMI on the same interface? Just because no OS is running doesn't necessarily mean that no code is futzing with the NIC.
I'm pretty sure we ran into this problem on our private interface a few months ago. As far as Linux knew, everything was fine. However, traffic couldn't be sent out of the interface. There are quite a few SuperMicro boards that utilize the controller. Do you have any idea when Intel is planning on releasing the fix?
These things happen sometimes because governments and other organizations secretly contract coders to hide these "backdoors" into products. This is what happens with proprietary software. And it's very common.
Awesome detective work and a great read too. Well done indeed!
Sounds like the packet is very specific, but if I put together an IDP sig to block it, I could end up blocking normal call traffic (and possibly other protocols too...)? Or is there something more specific to it? Just a 0x02 at the right offset and bam?
Great find BTW... pretty amazing.
Bill - These NICs do not have IPMI enabled. That's one of the first things Intel verified. From what I understand Intel maintains two EEPROMs for this controller - one with BMC and one without. Ours don't have it (and the EEPROM is quite short as a result). They do, however, support WOL which is why they are always receiving and processing traffic to some extent.
OK, so I now know that I have a bunch of equipment that is vulnerable after running the test, so how do I patch it if Intel has not published a solution?
So, if Intel has a fix and I have a server where I have observed this behavior... who can I contact to locate this tool/fix?
Brilliant sleuthing btw! That is even more obscure than the Ubuntu 12 cannot reload due to VGA conflict issue that surfaced at our company recently.
I'm reluctant to release the fix I have. I'll update my Intel POD page to include diffs between a "good" EEPROM and a "bad" EEPROM. Unfortunately the 82574L controllers I've fixed don't have the BMC enabled EEPROM, which seems to be far more widely used. Using my non-BMC fix on a BMC EEPROM could have disastrous consequences.
Dude... Awesome find, seriously. Have you got a crafted packet that one might use to replay on their own network?
Do you know wether or not packets received at virtual machines will affect the VM host? Do you know wether or not packets received just 'on the wire' - ie, not specifically addressed to the host, will also cause the same result (ie a router)?
So, wait, Intel has a fix that they haven't publicized because they don't know how widespread it is?! I'm having trouble believing that. Why would they not immediately release the fix for such a nasty bug?
Amazing. Thank you for writing this up. I enjoyed it thoroughly.
Not too long ago I went on a network hunt that took me another direction - you may enjoy reading my post: The little ssh that (sometimes) couldn't
Benoit - My interactions with Intel on this issue have been interesting, to say the least. It essentially got to the point where they considered this issue to be completely isolated to me. Once I deployed my fix it was "case closed" and they stopped my replying to further inquiries. The entire purpose of this post was to find other affected users (which has been successful).
Intel has a fix, they just need to release it.
Dayton - I've updated my post to include two variations of the packet. Look for the kriskinc.com link towards the top.
What this case teaches me is that debugging and troubleshooting in the modern technology solution becomes so complex and expensive that it just doesn't make sense. You don't actually need to find the root cause of failure; you need to address the failure by restoring the service. The simplest way to do that is to ensure that service is switched to another instance and to replace a defective instance. This is how all redundant arrays operate, be it disk spindles, network cards, or even servers in a datacenter cluster. Of course, in order to accomplish that, there should be some sophisticated software deployed able to control the service and to detect failures. Yes of course sophisticated software might have its own bugs, but here we start going in circles... :)
Yeah, and of course by eliminating troubleshooting and debugging you lose lots of fun... ;)
I have a 'Intel Corporation 82567LM-3 Gigabit Network Connection (rev 02)' in my office desktop. And I have with the frequency of approx once a month experienced very similar symptoms. Card stops working completely and requires full hard reboot (ifup/down, driver reloading, soft reboot nothing works with exception of shut down and unplugging power cable and plugging it back in).
I tried replaying you pcap in hopes of reproducing the problem. Alas, could not reproduce. I guess the problem I have is very similar though.
So, just to be clear. . . is 82574L the only Gbit Intel controller affected?
So just to be clear. . . is 82574L the only Intel Gbit controller affected?
well, a different approach to fixing it would be to somehow guarantee an inoculation packet always hit the nic first thing after powerup. maybe in the bootloader somewhere?
WHY THE FUCK does the Intel firmware care about anything above OSI layer 1?
This is why all firmware should be open source! We can't fix this without fucking Intel engineers!
These types of issues are scary indeed. I discovered an equally scary problem with motorola canopy wireless broadband access points and subscriber modules where a single packet would cause the units to reset into factory manufacturing mode, rendering them useless until private non-public secret keys were reloaded along with other one time factory manufacturing calibration data. With it, you could literally and irreversibly destroy a Canopy wireless network, potentially wiping out thousands of users all at once (and destroying the operator at the same time, of course). The response to these types of issues is usually denial and secrecy, which is why the policy of full disclosure is so important - because inertia being what it is, there is significant resistance to simply not addressing these problems in the first place otherwise.
Just tried this with enthusiasm on a 82578DM NIC. Alas does not appear to be vulnerable either.
Great detective work. Just out of curiosity - what model phone was sending out the problematic INVITE?
Kathleen - As far as I know, some configurations of the Intel 82574L controller are affected. From the responses I have received I'm certainly not the only person that can reproduce this issue with the 82574L and this traffic.
Clement - The original phone was a Yealink T22, which due to some missing error checking on their part and misconfiguration on our part caused these packets to be sent more frequently than you would imagine.
Great! Now I know just what to put in the SMTP responses to tell spammers to FOAD.
Many thanks!
We are Chinese!
We make it!
We Own them!
We Own you!
Nice work, thank you for posting.
I have an 82574L that so far I have NOT been able to kill with these packets. Do you have reports that some 82574L's are NOT vulnerable to this problem? I'd like to confirm that I haven't just missed something in my testing.
Interestingly, ethtool -e shows my EEPROM code at offset 0x60 to be:
0x0060 02 01 00 40 41 13 17 40 ff ff ff ff ff ff ff ff
which is almost, but not quite, what the third hunk of your EEPROM patch changes it to.
My card has PCI device ID 0x10d3. It is on a Supermicro X9SCL/X9SCM motherboard.
jrj - It's clear from the crowdsourced testing currently taking place that not all 82574L controllers are affected by this specific packet. What we don't know is how many are, why, and what other kinds of traffic could potentially cause this issue. That's what I'm trying to discover.
For what it is worth, I was unable to kill devices on my home network that have the Intel 82571GB and 82579V chipsets using tcpreplay-edit and the pcap files you provided.
Word 0x30 isn't the important part -- that's just PXE configuration. The valuable bit appears to be in word 0xf (offset 0x1f)... his new eeprom values have manageability disabled (previously "advanced passthru") It also has SER_EN (serial number enable) cleared, but I don't think that has anything do with it.
[Also note, based on e1000e driver docs, word 0xf (offset 0x1e) should have bit 1 set (0x5a), but those bits are "RESERVED" (read: undocumented) in the official datasheet.]
Ricky - Thank you for your comment. This is exactly the kind of collaboration I was hoping to jump start with this post. Please come back and let us know if you find anything else.
Interesting that you trustingly assume this is a bug, rather than a deliberate design feature.
Internet Off Switch. Something certain parties really, really wish existed. And are very likely working to make it so.
The only device I have with that chip in it is our checkpoint firewall... and I'm not going to use it as a target. :-) (I sent an email breakdown of all the bits that changed. At least as many as Intel has -- not so accurately -- documented.)
Nice work. I have a number of users with Intel 82579V cards that randomly hang up. They generally recover soon afterwards by themselves, but it's annoying to lose all your network connections.
Sometimes they'll work for weeks without a problem, other times they'll hang up 20 times a day.
I'm wondering now if this is a similar issue.
Hi Kristian
My machines all use the affected cards but seem immune from the bug.
They have very slightly different offsets from the affected ones you posted:
0x0010: ff ff ff ff 6b 02 69 83 43 10 d3 10 ff ff 58 a5
0x0030: c9 6c 50 31 3e 07 0b 46 84 2d 40 01 00 f0 06 07
0x0060: 00 01 00 40 48 13 13 40 ff ff ff ff ff ff ff ff
Running "ethtool -i eth1" gives:
driver: e1000e
version: 1.5.1-k
firmware-version: 1.8-0
Hi Kristian,
Think you'll be interested in this read:
http://www.versalogic.com/support/Downloads/PDF/Intel_82574L_Datasheet.pdf
Especially section 6.0.
Cheers,
dmy
Hi Kristian,
All my machines have the affected cards but appear immune from either of the replays you posted.
They have very subtly different offsets from the affected ones you've given:
0x0010: ff ff ff ff 6b 02 69 83 43 10 d3 10 ff ff 58 a5
0x0030: c9 6c 50 31 3e 07 0b 46 84 2d 40 01 00 f0 06 07
0x0060: 00 01 00 40 48 13 13 40 ff ff ff ff ff ff ff ff
driver: e1000e
version: 1.5.1-k
firmware-version: 1.8-0
I always appreciate tales of professional-grade sleuthing. Thanks for sharing.
That somehow reads as a fuckup on behalf of the Mainboard vendor if those are onboard NICs - seems as if they have enabled handling of passthrough traffic where the NIC/board doesn't have this capability. The NIC crashing is appropriate behaviour in this case, though for them not having a watchdog is a pity.
That somehow reads as a fuckup on behalf of the Mainboard vendor if those are onboard NICs - seems as if they have enabled handling of passthrough traffic where the NIC/board doesn't have this capability. The NIC crashing is appropriate behaviour in this case, though for them not having a watchdog is a pity.
Looking at the how-to-reproduce pages... is there a specific reason that you write "no VLAN switches"?
I've got all potentially affected NICs interfaces on VLAN trunks - does that make me safe from the issue generally, or would I just need to change the reproducing capture to test for it?
Looking at the how-to-reproduce page - why do you write "no VLAN switch"?
I have all potentially affected NICs on VLAN trunk ports - does that shield me from the issue generally, or do I just need to modify the reproducing capture in some way?
For the record of everyone,
the way that most implementations even for onboard, a warm reset or even a poweroff will not clear the state of the chip.
Most probably because of bmc/wol features they chip will always take power from the standby power rails.
Most warm reset of transitions from D3 to D0 will not cause a generic pcie link reset (most probable fast boot) they think that windows and linux will reset the interface while we attach modules (LOL!! -- personal joke)
You can now write
"I do VoIP ... and PoD"
What about disabling all kind of offloading ?
Hi,
I have just tested a NIC wich is NOT affected. Although, the EEPROM offset for 0x0030 is tha same as declared as affected:
# ethtool -e eth1 | grep -E "0x0010|0x0030|0x0060"
0x0010 10 10 ff ff 6b 02 ec 34 86 80 d3 10 ff ff 58 25
0x0030 c9 6c 50 31 3e 07 0b 46 84 2d 40 01 00 f0 06 07
0x0060 00 01 00 40 18 13 13 40 ff ff ff ff ff ff ff ff
There are two high probability subsystems that could cause this: 1. PCIe glue (source of the ASPM, 256b/128b, PCIe link training and PCIe posting credit NIC and system hangs); 2. ASF/BMC/sideband channel (source of a lot of nasty hard-to-debug issues); As the fix is a change of a single bit in the eeprom, this means it is very likely to be in (1) or (2). Issues with (1) are highly dependent on PCIe low-level behaviour, i.e. the entire PCIe config space and PCIe bridge undocumented bits in the case of the IOH and tends to depend on PCIe transaction type, not its contents at the bit level (just size, destination, etc). (2) depends on how the 82574L is wired and its EEPROM only, as well as data traffic contents, since the NIC is actually opening the frames to check for MAC destination, WoL content, etc.
This is likely to end up properly documented in the internal up-to-date Specification Update manual for the 82574L, see if your hardware OEM can get it through their developer channel with Intel. Alternatively, the Intel people in LKML can get indirect access to that information, all you need to do is to write a proper report to LKML with the results of this crowdsourcing effort. The driver can warn the user of a dangerous eeprom condition, which would be valuable indeed...
And that logic is why we cant have nice things. Fight the symptoms, not the cause.... Incredible, I assume you are a manager?
Kristian :
Very nice detective work on your part, but even more kudos for the smart write-up and posting in your blog. Best success in getting this issue acknowledged and remediated by the manufacturer. Thanks very much and keep up the good work!
Mark Strelecki
Atlanta, GA. USA
You got a follower :)
Great piece of detective work, Kris! As a developer who troubleshoots network problems, I feel the pain, frustration, tearing of hair et al!
Glad to see that Ostinato helped your investigations and dig down right upto the offending packet offset and values! If you have any feedback or suggestions regarding Ostinato, do drop by the mailing list!
Srivats
Creator and Lead-Developer, Ostinato (http://ostinato.org)
Great detective work, Kris! As a developer who troubleshoots network problems, I feel the pain, frustration, tearing of hair et al!
Glad to see that Ostinato helped your investigations and dig down right upto the offending packet offset and values! If you have any feedback or suggestions regarding Ostinato, do drop by the mailing list!
Srivats
Creator and Lead-Developer, Ostinato (http://ostinato.org)
Is there any Bug ID or CVE for this issue?
One request: can you add the firmware version (as reported by ethtool -i) and this from an incorrect eeprom and a correct eeprom?
We are using about 1600 82574L cards.
We've not managed to reproduce this just yet..
Dumping the eeprom of each of those and checking offset 0x0010 through 0x001F shows these values: (first column is the number of times the value was seen)
1 0x0010 01 01 ff ff 6b 02 0a 06 d9 15 d3 10 ff ff 58 80
90 0x0010 01 01 ff ff 6b 02 0a 06 d9 15 d3 10 ff ff 58 83
199 0x0010 01 01 ff ff 6b 02 0a 06 d9 15 d3 10 ff ff 58 a5
266 0x0010 01 01 ff ff 6b 02 d3 10 d9 15 d3 10 ff ff 58 83
266 0x0010 01 01 ff ff 6b 02 d3 10 d9 15 d3 10 ff ff 58 85
8 0x0010 08 d5 03 68 2f a4 5e 11 86 80 5e 10 86 80 65 b1
58 0x0010 08 d5 06 68 2f a4 5e 11 86 80 5e 10 86 80 65 b1
66 0x0010 08 d5 07 68 2f a4 5e 11 86 80 5e 10 86 80 65 b1
96 0x0010 08 d5 08 68 2f a4 5e 11 86 80 5e 10 86 80 65 b1
164 0x0010 69 e4 03 81 6b 02 1f a0 86 80 d3 10 ff ff 58 9c
97 0x0010 69 e4 04 81 6b 02 1f a0 86 80 d3 10 ff ff 58 9c
115 0x0010 69 e4 05 81 6b 02 1f a0 86 80 d3 10 ff ff 58 9c
48 0x0010 69 e4 06 81 6b 02 1f a0 86 80 d3 10 ff ff 58 9c
103 0x0010 69 e4 07 81 6b 02 1f a0 86 80 d3 10 ff ff 58 9c
Looking closer:
* the values starting with '01 01' seem to be linked with firmware version 1.9-0
* the values starting with '08 d5' seem to be linked with firmware version 5.11-2
* the values starting with '69 e4' seem to be linked with firmware version 1.8-0
Given that we have no eeprom that contains 'ff ff' at offset 0x0010 makes us suspect that we have none of the affected cards..
We contacted Intel to receive more information about which cards are/are not affected.
I've got a 6015V-MTB with X7DVL-i Board, and it's affected by the lag-bug at: https://sites.google.com/a/lucidpixels.com/web/blog/supermicrox9scm-fissues
pcie_aspm=off does not help.
ethtool -e eth0
Offset Values
------ ------
0x0000 00 30 48 9c 13 8a 10 0d ff ff 1c 20 ff ff ff ff
0x0010 50 20 ff ff 0b 34 96 10 d9 15 96 10 86 80 60 31
0x0020 04 00 96 10 00 5c c8 02 00 54 00 00 00 00 00 00
Hi Kristian - we posted the offending packet in a capture on CloudShark.org if you want to be able to easily pass it around. We included an annotation too that points back to your blog post. You can see it all here.
Great article, and an amazing find!
I have tested with a 82574L controller on a Tyan S7002 motherboard. I'm not able to reproduce the issue.
Intel "considered this issue to be completely isolated" to your setup.
Anyone been able to reproduce this issue?
I have one machine that has the eeprom with ff ff at 0x0010, here's the output of ethtool -i:
driver: e1000e
version: 1.2.20-k2
firmware-version: 1.8-0
bus-info: 0000:07:00.0
Here's the output of ethtool -e from the that machine:
0x0010 ff ff ff ff 6b 02 02 55 f1 10 d3 10 ff ff 58 a6
Right now I can't kill it to test, but we're looking into another such machine ATM and will see what happens with it in a bit.
10, 20, 30, and 40 are multiples of 10 not powers of 10
ethtool -e eth1 | grep 0x0010
0x0010 ff ff ff ff c3 10 02 15 d9 15 02 15 00 00 00 00
ethtool -i eth1
driver: e1000e
version: 1.2.20-k2
firmware-version: 0.13-4
bus-info: 0000:00:19.0
Not vulnerable
Kudos for the awesome detective work, and the detailed write-up.
Sorry I don't have more to contribute to such an effort.
-ASB: http://XeeMe.com/AndrewBaker
That's a fantastically scary bug. Thanks for all the careful tracking and detective work.
I assume I'm not the only one thinking, "what if every e1000 out there manifests this problem?" Icky, very icky indeed.
One more request: is it possible to post the entire eeprom of a bad card?
We ran into this problem on a server we had in our corporate environment running KVM VM. It hosed some VM's from responding every couple of months. Then one time almost all of the VM's plus the host were non-responsive. This again happened when we moved to a new co-location for our production environment.
The solution we used was the same as the one "Gordon Messmer" mentioned. We used the shell script to update the EEPROM on our 82547L chip. We haven't had any issues for about 7 months.
Does anybody know if this affects the 82576 or 82580 chips? I think that these are the dual and quad versions of the 82574, but I'm not sure about that.
Unable to replicate with 82574L.
@ Mike Ireton or any one els that has heard of the Motorola Canopy bug he mentioned. If you have any other info, i'd like to discuss this.
@ Kristian Kielhofner, Thanks for this. Some A+ Sleuthing going on there.
Also unable to replicate... Has anyone other than the author been able to reproduce this?
Re 82576 and 82580 cards:
We have some onboard cards that are identified as 82576 but these use the 'igb' driver and not the 'e1000e' driver as the 82574L... so I don't think they are the same...
(I'm obviously not sure about that..)
Thoroughly compelling narrative, and inspiringly comprehensive diagnostics, Kris! Thank you!
The part that stimulates my thinking is the inoculation. If your findings are correct, then people testing their NICs must ensure that they really restart or reset their NICs before testing, since there is a pretty good chance that they've experienced packets where byte 1151 is an inoculating value rather than a no-effect or death value.
I wonder what are the consequences of values other that 0x31, 0x32, 0x33, 0x34 at byte 1151? No effect, or inoculation. The latter would make this problem extremely hard to observe and rare to experience.
also I am unable to replicate the bug with our 82574L.
lshw gives this output:
capabilities: pm msi pciexpress msix bus_master cap_list ethernet physical tp 10bt 10bt-fd 100bt 100bt-fd 1000bt-fd autonegotiation
configuration: autonegotiation=on broadcast=yes driver=e1000e driverversion=1.5.1-k firmware=2.1-2 latency=0 link=no multicast=yes port=twisted pair
kernel version: 3.2.0-37-generic (64 bit)
with these EEPROM values:
0x0010 ff ff ff ff 6b 02 00 00 d9 15 d3 10 ff ff 58 a5
0x0030 c9 6c 50 31 3e 07 0b 46 84 2d 40 01 00 f0 06 07
0x0060 02 01 00 40 41 13 17 40 ff ff ff ff ff ff ff ff
Ow and following info:
ethtool -i eth1
driver: e1000e
version: 1.5.1-k
firmware-version: 2.1-2
bus-info: 0000:04:00.0
Press release from Intel: http://communities.intel.com/community/wired/blog/2013/02/07/intel-82574l-gigabit-ethernet-controller-statement
Guys,
If you find your NIC vulnerable -- please post the details (versions, whether it is integrated or not, and whatnot) AND the EEPROM dump BEFORE you patched the NIC. This should help us all locate the issue.
WBR,
dmy
This is fascinating. Do the packets have to have valid structure? Do they have to be unicast? I can see a "weaponized" form of this as ARP or multicast or some other 1-to-many frame type, which would take out an entire subnet with a single packet...
Absolutely stellar investigation, bravo!
What's up with your picture you look like you're from jersey shore?? LOL
@Kristian
Which motherboard did you test with?
I tried this on one of our machines here. It uses a SuperMicro motherboard with an integrated 82574L.
I have not been able to replicate it. However, I am wondering in integrated chips are not affected, and only add-on cards are?
I tried this on one of our machines here. It uses a SuperMicro motherboard with an integrated 82574L.
I have not been able to replicate it. However, I am wondering in integrated chips are not affected, and only add-on cards are?
@Kristian Kielhofner Congrats Sir, you've just discovered the Internet Kill-Switch!
The “red telephone,” used to shut down the entire Internet comes to mind.
You discovered howto immunize friends and kill enemies in CyberWars, probably even more..
Do governments have an Internet kill switch? Yes, see Egypt & Syria they're good examples. We know China is doing Cyberwars, they are beyond Kill-Switches.
Wiki: Internet kill switch
We know Goverments deploy hardware that they can control when needed. Smartphones are the best examples for Goverment issued backdoors, next to some Intel Hardware (including NICs).
We can't protect the people.
There is a whole thread about the issue in Intel messageboards, has been there since September. Intel DZ77GA-70K motherboard with 82574L suffering from the same fault. No fix yet or official reply from Intel about the matter.
http://communities.intel.com/thread/31828?start=0&tstart=0
The potential for deep and almost intractable issues like this are why NASA flew the shuttle with core memory (little magnetic donuts for memory instead of RAM chips) for a long time after it was obsolete.
...the behavior of the controller depended completely on the value of this specific address in the first received packet to match that address.
This confuses me.
The controller fails if a packet goes through it with 0x32 or 0x33 in position 0x47F...
if it is "the first received packet..." first received after what? Power-on? "... to match that address"? What address? 0x47f?
Also, the nothing/kill/immunization pattern: the controller can be immunized only by the 0x47F value in the very first packet it receives? First after what? Of any kind? Or only a packet at least 0x480 bytes long?
Finally - did Intel ever reveal what a "death packet" actually did to the controller?
H-Online has reported that this problem only occurs with one motherboard:
http://www.h-online.com/security/news/item/Intel-Packet-of-Death-not-Intel-s-problem-1801537.html
The identity of the board manufacturer was not disclosed by Intel or in the "packet of death" discoverer's blog posting. But readers will find it in a Wired report, which says that Taiwanese manufacturer Lex CompuTech (which operates under the name Synertron Technology in the US) was the provider of the incorrectly flashed motherboard.
Many of these comments/questions have been addressed in my update post:
http://blog.krisk.org/2013/02/packets-of-death-update.html
Rich - Yes, the first received packet after power on. This applies to the "packets of death" or the inoculation packets. Keep in mind there is also at least one value that has no effect at all. Intel still hasn't responded as to why/how this behavior occurs. Until we know that the only way to know (exhaustively and conclusively) which adapter/EEPROM combinations are affected is to fuzz them, I guess...
It actually reminded me about: https://bugzilla.kernel.org/show_bug.cgi?id=47331 , are they same?
Post a Comment