After my original post on “packets of death” I’ve spent the last couple of weeks receiving reports from users all over the world ranging from:
- Able to reproduce on 82574L with your “packets of death”
- Not able to reproduce on 82574L or any other controller
-
Not able to reproduce with your “packets of death” but experiencing
identical, sporadic failures across a wide range of controllers
Of
course the last category intrigued me the most. There seem to be an
awful lot of people experiencing sporadic failures of their ethernet
controllers but many of them (as I noted in another update)
don’t have the time or tools to diagnose the issue further. In most
cases the symptoms are identical to what I described in my original
post:
- Ethernet controller loses link (or reports some other hardware error)
- Varying amounts of time since boot (hours, days, weeks)
- Can only be resolved by a reboot or in some cases a complete power cycle
Many
of these users have been dealing with these failures in various ways
but have been unable to find a root cause. I’ve created a tool to help
them with their diagnosis. It’s called findpod and it’s been tested on various Debian-based Linux distributions. Findpod uses the excellent ifplugd daemon, the venerable tcpdump, and screen.
Once
installed and started iflpugd will patiently wait to receive link
status notifications from the Linux kernel. Once link is detected on
the target interface it will start a tcpdump session running inside of
screen. This tcpdump session will log all packets sent and received on
that interface. Here’s the thing - many of these failures are reported
after days or weeks of processed traffic - the tcpdump capture file
could easily reach several gigabytes or more! Here’s where one key
trick in findpod comes into play - by default findpod will only log the
last 100MB sent or received on the target interface. As long as ifplugd
doesn’t report any link failures tcpdump will keep writing to the same
100MB circular capture file.
What
happens when the interface loses link? This is the second unique feature of findpod. When ifplugd reports a loss of link it will wait for 30
seconds before stopping the packet capture and moving the capture file
to a meaningful (and known) name. If you think your ethernet controller
failures could be related to the types of traffic you’re sending or
receiving (as I discovered with my “packets of death”) findpod will help
you narrow it down to (at most) 100MB of network traffic, even if the
capture runs for weeks and your interface handles GBs of data!
Of
course (more than likely) it’s even easier than that; if your link loss
is being caused by a specific received packet it will be the last
packet in the capture file provided by findpod and you’ll only have a
100MB capture file to work with. If your issue is anything like mine you should be able to isolate it down to a specific packet that you can feed to tcpreplay; reproducing your controller issue on demand.
Please tell me about your experiences with findpod. As always, comments and suggestions are welcome!
Wednesday, February 20, 2013
Friday, February 8, 2013
Packets of Death - UPDATE
UPDATE - Intel has pointed me towards the successor to the 82574, which includes some of the features I suggest here. I think it's safe to say we're all looking forward to this chip hitting the streets!
The last 48 hours has been interesting, to say the least.
My original post gathered much more attention than I originally thought. I’ll always remember being on a conference call and having someone tell me “Hey, you’re on Slashdot”. Considering the subject matter I suppose I should have expected that.
As of today, here’s what I know:
Many of you have shared the results of your testing. The vast majority of tested Intel ethernet controllers do not appear to be affected by this issue.
Intel has responded with an expanded technical explanation of the issue. I also received a very pleasant and professional phone call from Douglas Boom (at Intel) to update me on their assessment of the situation and discuss any ongoing concerns or problems I may have. Thank you Doug and well done Intel! Note to other massive corporations that could be presented with issues like this: do what Intel did.
To summarize their response, Intel says that a misconfigured EEPROM caused this issue. The EEPROM is written by the motherboard manufacturer and not Intel. Intel says my motherboard manufacturer did not follow their published guidelines for this process. Based on what I’ve seen, how my issue was fixed, and what I’m learning from the crowdsourced testing process this seems like a perfectly plausible explanation. Once again, thanks Intel!
However, I still don’t believe this issue is completely isolated to this specific instance and one motherboard manufacturer. For one, I have received at least two confirmed reports from people who were able to reproduce this issue - my “packet of death” shutting down 82574L hardware from different motherboard manufacturers. This doesn’t surprise me at all.
One thing we’re reminded of in this situation is just how complex all of these digital systems have become. We’re a long way from configuring ethernet adapters with IRQ jumpers. Intel has designed an incredibly complex ethernet controller - the datasheet is 490 pages long! Of course I’m not faulting them for this - the features available in this controller (or many other controllers) dictate this level of complexity - management/IPMI features, WOL, various offloading mechanisms, interrupt queues, and more. This complexity doesn’t even scratch the surface of the various other systems involved in getting data across the internet and into your eyeballs!
Like any sufficiently advanced product all of these features are driven by a configuration mechanism. The Linux kernel module for the 82574L (e1000e) has various options that can be passed to modify the behavior of the adapter. Makes sense. If I passed some stupid or unknown parameter to this module I would expect it to return with some kind of error informing me of my mistake. I’m only human, mistakes are going to happen.
At a lower level Intel has exposed these EEPROM configuration parameters to control various aspects of the controller. As Intel says these EEPROM values are to be set by the motherboard manufacturer. Here’s where the problem lies - it’s certainly possible this could be done incorrectly. Motherboard manufacturers are human and they make mistakes too.
Unfortunately, as we’ve learned in this case, there isn’t quite the same level of feedback when EEPROM misconfigurations happen. In my previous example if I pass unknown parameters to a kernel module it’s going to come back and say “Hey - I don’t know what that is (dummy)” and exit with an error.
As I’ve shown in some cases (mine) if an EEPROM is misconfigured everything appears normal until some insanely specific packet is received. Then the controller shuts down, for some reason.
Does that behavior make sense to anyone?
I suggest the following:
1) Make future controllers have as much in-hardware sane behavior as possible when unknown conditions are encountered. Error checking, basically. Users can input data on a web form, that’s why there’s error checking. Everyone knows users do stupid things. Clearly some of the people programming Intel EEPROMs for motherboard OEMs do stupid things too. What is sane default behavior? EEPROM error encountered = adapter shutdown and error message. Give the user notification and provide some mechanism for EEPROM validation and management...
2) Put more EEPROM validation in operating system drivers. Intel maintains ethernet drivers for various platforms. Why aren’t these drivers doing more validation of the adapter EEPROM? If my EEPROM was so badly misconfigured, why couldn’t the e1000e module have discovered that and notified me?
3) Produce and support an external tool for EEPROM testing, programming, and updating. In the course of working with Intel last fall I was provided a version of this tool for my testing so I know it exists. While I can understand why you don’t want random users messing with their EEPROM (and causing potential support nightmares) it seems the benefits would clearly outweigh any potential problems (of which there are already plenty).
The reality is Intel has no idea how many systems are affected by this issue or could be affected by issues like it. How could they? They’re expecting motherboard OEMs to follow their instructions (and understandably so). Just look at the combination of variables required to reproduce this issue:
- Intel 82574L
- Various specific misconfigured bytes in the EEPROM
- An insanely specific packet with the right value at just the right byte, received at a specific time
While most people weren’t able to reproduce this issue with their controller and EEPROM combinations it did kick off various discussions of periodic, random, sporadic failures across a wide range of ethernet adapters and general computing weirdness. A quick Google search returns a wide assortment of complaints with these adapters (and others like it) from a whole slew of users. EEPROM corruption. Random adapter resets. Packet drops. Various latency issues. PCI bus scan errors. ASPM problems. The list goes on and on.
Perhaps the “packet of death” for a slightly misconfigured Intel 82579 (for example) is my packet shifted 20 bytes in one direction or the other. Who knows? Please, please, please Intel - lets do everyone a favor and get these EEPROMs under control. End users update firmware all of the time - routers, set-top boxes, sometimes even their cars! Why can’t we have some utility to make sure our ethernet adapters aren’t just waiting to freak out when they receive the wrong packet?
I don’t believe in magic, swamp gas, sun spots, or any of the other “explanations” offered for some of the random strange behavior we often see with these complex devices (ethernet adapters or otherwise). That’s why I spent so long working on this issue to find a root cause (well that and screaming customers). I, like anyone else, encounter bugs and general weirdness in devices and software everyday in my life. Most of the time how do I respond to these bugs? I reboot, shrug my shoulders, say “that was weird”, and move on. Meanwhile I know, deep down, that there is a valid explanation for what just happened. Just like there was with my ethernet controllers.
Even with the explanation offered by Intel we could go much deeper. Why these bytes at that location? Why this packet? What’s up with the “inoculation” effect of some of the values? There are still many unanswered questions.
I’ve enjoyed reading many others report their tales of “extreme debugging” with the digital devices in their lives. It seems I’m not the only one that isn’t always satisfied with saying “that was weird” and moving on.
I've said it before and I'll say it again - I love the internet!
The last 48 hours has been interesting, to say the least.
My original post gathered much more attention than I originally thought. I’ll always remember being on a conference call and having someone tell me “Hey, you’re on Slashdot”. Considering the subject matter I suppose I should have expected that.
As of today, here’s what I know:
Many of you have shared the results of your testing. The vast majority of tested Intel ethernet controllers do not appear to be affected by this issue.
Intel has responded with an expanded technical explanation of the issue. I also received a very pleasant and professional phone call from Douglas Boom (at Intel) to update me on their assessment of the situation and discuss any ongoing concerns or problems I may have. Thank you Doug and well done Intel! Note to other massive corporations that could be presented with issues like this: do what Intel did.
To summarize their response, Intel says that a misconfigured EEPROM caused this issue. The EEPROM is written by the motherboard manufacturer and not Intel. Intel says my motherboard manufacturer did not follow their published guidelines for this process. Based on what I’ve seen, how my issue was fixed, and what I’m learning from the crowdsourced testing process this seems like a perfectly plausible explanation. Once again, thanks Intel!
However, I still don’t believe this issue is completely isolated to this specific instance and one motherboard manufacturer. For one, I have received at least two confirmed reports from people who were able to reproduce this issue - my “packet of death” shutting down 82574L hardware from different motherboard manufacturers. This doesn’t surprise me at all.
One thing we’re reminded of in this situation is just how complex all of these digital systems have become. We’re a long way from configuring ethernet adapters with IRQ jumpers. Intel has designed an incredibly complex ethernet controller - the datasheet is 490 pages long! Of course I’m not faulting them for this - the features available in this controller (or many other controllers) dictate this level of complexity - management/IPMI features, WOL, various offloading mechanisms, interrupt queues, and more. This complexity doesn’t even scratch the surface of the various other systems involved in getting data across the internet and into your eyeballs!
Like any sufficiently advanced product all of these features are driven by a configuration mechanism. The Linux kernel module for the 82574L (e1000e) has various options that can be passed to modify the behavior of the adapter. Makes sense. If I passed some stupid or unknown parameter to this module I would expect it to return with some kind of error informing me of my mistake. I’m only human, mistakes are going to happen.
At a lower level Intel has exposed these EEPROM configuration parameters to control various aspects of the controller. As Intel says these EEPROM values are to be set by the motherboard manufacturer. Here’s where the problem lies - it’s certainly possible this could be done incorrectly. Motherboard manufacturers are human and they make mistakes too.
Unfortunately, as we’ve learned in this case, there isn’t quite the same level of feedback when EEPROM misconfigurations happen. In my previous example if I pass unknown parameters to a kernel module it’s going to come back and say “Hey - I don’t know what that is (dummy)” and exit with an error.
As I’ve shown in some cases (mine) if an EEPROM is misconfigured everything appears normal until some insanely specific packet is received. Then the controller shuts down, for some reason.
Does that behavior make sense to anyone?
I suggest the following:
1) Make future controllers have as much in-hardware sane behavior as possible when unknown conditions are encountered. Error checking, basically. Users can input data on a web form, that’s why there’s error checking. Everyone knows users do stupid things. Clearly some of the people programming Intel EEPROMs for motherboard OEMs do stupid things too. What is sane default behavior? EEPROM error encountered = adapter shutdown and error message. Give the user notification and provide some mechanism for EEPROM validation and management...
2) Put more EEPROM validation in operating system drivers. Intel maintains ethernet drivers for various platforms. Why aren’t these drivers doing more validation of the adapter EEPROM? If my EEPROM was so badly misconfigured, why couldn’t the e1000e module have discovered that and notified me?
3) Produce and support an external tool for EEPROM testing, programming, and updating. In the course of working with Intel last fall I was provided a version of this tool for my testing so I know it exists. While I can understand why you don’t want random users messing with their EEPROM (and causing potential support nightmares) it seems the benefits would clearly outweigh any potential problems (of which there are already plenty).
The reality is Intel has no idea how many systems are affected by this issue or could be affected by issues like it. How could they? They’re expecting motherboard OEMs to follow their instructions (and understandably so). Just look at the combination of variables required to reproduce this issue:
- Intel 82574L
- Various specific misconfigured bytes in the EEPROM
- An insanely specific packet with the right value at just the right byte, received at a specific time
While most people weren’t able to reproduce this issue with their controller and EEPROM combinations it did kick off various discussions of periodic, random, sporadic failures across a wide range of ethernet adapters and general computing weirdness. A quick Google search returns a wide assortment of complaints with these adapters (and others like it) from a whole slew of users. EEPROM corruption. Random adapter resets. Packet drops. Various latency issues. PCI bus scan errors. ASPM problems. The list goes on and on.
Perhaps the “packet of death” for a slightly misconfigured Intel 82579 (for example) is my packet shifted 20 bytes in one direction or the other. Who knows? Please, please, please Intel - lets do everyone a favor and get these EEPROMs under control. End users update firmware all of the time - routers, set-top boxes, sometimes even their cars! Why can’t we have some utility to make sure our ethernet adapters aren’t just waiting to freak out when they receive the wrong packet?
I don’t believe in magic, swamp gas, sun spots, or any of the other “explanations” offered for some of the random strange behavior we often see with these complex devices (ethernet adapters or otherwise). That’s why I spent so long working on this issue to find a root cause (well that and screaming customers). I, like anyone else, encounter bugs and general weirdness in devices and software everyday in my life. Most of the time how do I respond to these bugs? I reboot, shrug my shoulders, say “that was weird”, and move on. Meanwhile I know, deep down, that there is a valid explanation for what just happened. Just like there was with my ethernet controllers.
Even with the explanation offered by Intel we could go much deeper. Why these bytes at that location? Why this packet? What’s up with the “inoculation” effect of some of the values? There are still many unanswered questions.
I’ve enjoyed reading many others report their tales of “extreme debugging” with the digital devices in their lives. It seems I’m not the only one that isn’t always satisfied with saying “that was weird” and moving on.
I've said it before and I'll say it again - I love the internet!
Wednesday, February 6, 2013
Packets of Death
When you're done reading this check out my update! Experiencing similar ethernet controller issues but don't know where to start?
UPDATE: See the packets and find out if you're affected here.
UPDATE 2: Yes, I've reproduced this issue regardless of OS, ASPM state/settings, or software firewall settings. Obviously if you have a layer 2/3 firewall in front of an affected interface you'll be ok.
Packets of death. I started calling them that because that’s exactly what they are.
Star2Star has a hardware OEM that has built the last two versions of our on-premise customer appliance. I’ll get more into this appliance and the magic it provides in another post. For now let’s focus on these killer packets.
About a year ago we released a refresh of this on-premise equipment. It started off simple enough, pretty much just standard Moore’s Law stuff. Bigger, better, faster, cheaper. The new hardware was 64-bit capable, had 8X as much RAM, could accommodate additional local storage, and had four Intel (my preferred ethernet controller vendor) gigabit ethernet ports. We had (and have) all kinds of ideas for these four ports. All in all it was pretty exciting.
This new hardware flew through performance and functionality testing. The speed was there and the reliability was there. Perfect. After this extensive testing we slowly rolled the hardware out to a few beta sites. Sure enough, problems started to appear.
All it takes is a quick Google search to see that the Intel 82574L ethernet controller has had at least a few problems. Including, but not necessarily limited to, EEPROM issues, ASPM bugs, MSI-X quirks, etc. We spent several months dealing with each and every one of these. We thought we were done.
We weren’t. It was only going to get worse.
I thought I had the perfect software image (and BIOS) developed and deployed. However, that’s not what the field was telling us. Units kept failing. Sometimes a reboot would bring the unit back, usually it wouldn’t. When the unit was shipped back, however, it would work when tested.
Wow. Things just got weird.
The weirdness continued and I finally got to the point where I had to roll my sleeves up. I was lucky enough to find a very patient and helpful reseller in the field to stay on the phone with me for three hours while I collected data. This customer location, for some reason or another, could predictably bring down the ethernet controller with voice traffic on their network.
Let me elaborate on that for a second. When I say “bring down” an ethernet controller I mean BRING DOWN an ethernet controller. The system and ethernet interfaces would appear fine and then after a random amount of traffic the interface would report a hardware error (lost communication with PHY) and lose link. Literally the link lights on the switch and interface would go out. It was dead.
Nothing but a power cycle would bring it back. Attempting to reload the kernel module or reboot the machine would result in a PCI scan error. The interface was dead until the machine was physically powered down and powered back on. In many cases, for our customers, this meant a truck roll.
While debugging with this very patient reseller I started stopping the packet captures as soon as the interface dropped. Eventually I caught on to a pattern: the last packet out of the interface was always a 100 Trying provisional response, and it was always a specific length. Not only that, I ended up tracing this (Asterisk) response to a specific phone manufacturer’s INVITE.
I got off the phone with the reseller, grabbed some guys and presented my evidence. Even though it was late in the afternoon on a Friday, everyone did their part to scramble and put together a test configuration with our new hardware and phones from this manufacturer.
We sat there, in a conference room, and dialed as fast as our fingers could. Eventually we found that we could duplicate the issue! Not on every call, and not on every device, but every once in a while we could crash the ethernet controller. However, every once in a while we couldn’t at all. After a power cycle we’d try again and hit it. Either way, as anyone who’s tried to diagnose a technical issue knows the first step is duplicating the problem. We were finally there.
Believe me, it took a long time to get here. I know how the OSI stack works. I know how software is segmented. I know that the contents of a SIP packet shouldn’t do anything to an ethernet adapter. It just doesn’t make any sense.
Between packet captures on our device and packet captures from the mirror port on the switch we were finally able to isolate the problem packet. Turns out it was the received INVITE, not the transmitted 100 Trying! The mirror port capture never saw the 100 Trying hit the wire.
Now we needed to look at this INVITE. Maybe the userspace daemon processing the INVITE was the problem? Maybe it was the transmitted 100 Trying? One of my colleagues suggested we shutdown the SIP software and see if the issue persisted. No SIP software running, no transmitted 100 Trying.
First we needed a better way to transmit the problem packet. We isolated the INVITE transmitted from the phone and used tcpreplay to play it back on command. Sure enough it worked. Now, for the first time in months, we could shut down these ports on command with a single packet. This was significant progress and it was time to go home, which really meant it was time to set this up in the lab at home!
Before I go any further I need to give another shout out to an excellent open source piece of software I found. Ostinato turns you into a packet ninja. There’s literally no limit to what you can do with it. Without Ostinato I could have never gotten beyond this point.
With my packet Swiss army knife in hand I started poking and prodding. What I found was shocking.
It all starts with a strange SIP/SDP quirk. Take a look at this SDP:
v=0
o=- 20047 20047 IN IP4 10.41.22.248
s=SDP data
c=IN IP4 10.41.22.248
t=0 0
m=audio 11786 RTP/AVP 18 0 18 9 9 101
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:0 PCMU/8000
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:9 G722/8000
a=rtpmap:9 G722/8000
a=fmtp:101 0-15
a=rtpmap:101 telephone-event/8000
a=ptime:20
a=sendrecv
Wireshark picture: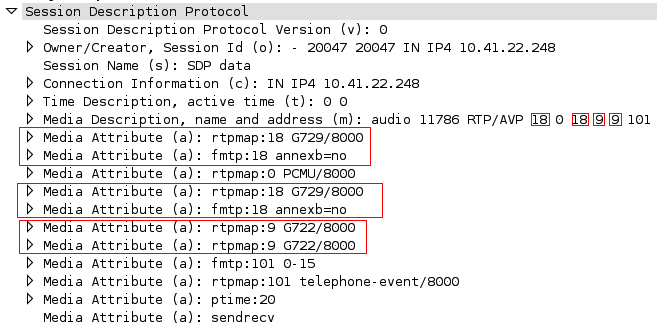
Yes, I saw it right away too. The audio offer is duplicated and that’s a problem but again, what difference should that make to an Ethernet controller?!? Well, if nothing else it makes the ethernet frame larger...
But wait, there were plenty of successful ethernet frames in these packet captures. Some of them were smaller, some were larger. No problems with them. It was time to dig into the problem packet. After some more Ostinato-fu and plenty of power cycles I was able to isolate the problem pattern (with a problem frame).
Warning: we’re about to get into some hex.
The interface shutdown is triggered by a specific byte value at a specific offset. In this case the specific value was hex 32 at 0x47f. Hex 32 is an ASCII 2. Guess where the 2 was coming from?
a=ptime:20
All of our SDPs were identical (including ptime, obviously). All of the source and destination URIs were identical. The only difference was the Call-IDs, tags, and branches. Problem packets had just the right Call-ID, tags, and branches to cause the “2” in the ptime to line up with 0x47f.
BOOM! With the right Call-IDs, tags, and branches (or any random garbage) a “good packet” could turn into a “killer packet” as long as that ptime line ended up at the right address. Things just got weirder.
While generating packets I experimented with various hex values. As if this problem couldn’t get any weirder, it does. I found out that the behavior of the controller depended completely on the value of this specific address in the first received packet to match that address. It broke down to something like this:
Byte 0x47f = 31 HEX (1 ASCII) - No effect
Byte 0x47f = 32 HEX (2 ASCII) - Interface shutdown
Byte 0x47f = 33 HEX (3 ASCII) - Interface shutdown
Byte 0x47f = 34 HEX (4 ASCII) - Interface inoculation
Bad:

Good:

When I say “no effect” I mean it didn’t kill the interface but it didn’t inoculate the interface either (more on that later). When I say the interface shutdown, well, remember my description of this issue - the interface went down. Hard.
With even more testing I discovered this issue with every version of Linux I could find, FreeBSD, and even when the machine was powered up complaining about missing boot media! It’s in the hardware; the OS has nothing to do with it. Wow.
To make matters worse, using Ostinato I was able to craft various versions of this packet - an HTTP POST, ICMP echo-request, etc. Pretty much whatever I wanted. With a modified HTTP server configured to generate the data at byte value (based on headers, host, etc) you could easily configure an HTTP 200 response to contain the packet of death - and kill client machines behind firewalls!
I know I’ve been pointing out how weird this whole issue is. The inoculation part is by far the strangest. It turns out that if the first packet received contains any value (that I can find) other than 1, 2, or 3 the interface becomes immune from any death packets (where the value is 2 or 3). Also, valid ptime attributes are defined inpowers (edit: multiples) of
10 - 10, 20, 30, 40. Depending on Call-ID, tag, branch, IP, URI, etc
(with this buggy SDP) these valid ptime attributes line up perfectly.
Really, what are the chances?!?
All of a sudden it’s become clear why this issue was so sporadic. I’m amazed I tracked it down at all. I’ve been working with networks for over 15 years and I’ve never seen anything like this. I doubt I’ll ever see anything like it again. At least I hope I don’t...
I was able to get in touch with two engineers at Intel and send them a demo unit to reproduce the issue. After working with them for a couple of weeks they determined there was an issue with the EEPROM on our 82574L controllers.
They were able to provide new EEPROM and a tool to write it out. Unfortunately we weren’t able to distribute this tool and it required unloading and reloading the e1000e kernel module, so it wouldn’t be preferred in our environment. Fortunately (with a little knowledge of the EEPROM layout) I was able to work up some bash scripting and ethtool magic to save the “fixed” eeprom values and write them out on affected systems. We now have a way to detect and fix these problematic units in the field. We’ve communicated with our vendor to make sure this fix is applied to units before they are shipped to us. What isn’t clear, however, is just how many other affected Intel ethernet controllers are out there.
I guess we’ll just have to see...
UPDATE: See the packets and find out if you're affected here.
UPDATE 2: Yes, I've reproduced this issue regardless of OS, ASPM state/settings, or software firewall settings. Obviously if you have a layer 2/3 firewall in front of an affected interface you'll be ok.
Packets of death. I started calling them that because that’s exactly what they are.
Star2Star has a hardware OEM that has built the last two versions of our on-premise customer appliance. I’ll get more into this appliance and the magic it provides in another post. For now let’s focus on these killer packets.
About a year ago we released a refresh of this on-premise equipment. It started off simple enough, pretty much just standard Moore’s Law stuff. Bigger, better, faster, cheaper. The new hardware was 64-bit capable, had 8X as much RAM, could accommodate additional local storage, and had four Intel (my preferred ethernet controller vendor) gigabit ethernet ports. We had (and have) all kinds of ideas for these four ports. All in all it was pretty exciting.
This new hardware flew through performance and functionality testing. The speed was there and the reliability was there. Perfect. After this extensive testing we slowly rolled the hardware out to a few beta sites. Sure enough, problems started to appear.
All it takes is a quick Google search to see that the Intel 82574L ethernet controller has had at least a few problems. Including, but not necessarily limited to, EEPROM issues, ASPM bugs, MSI-X quirks, etc. We spent several months dealing with each and every one of these. We thought we were done.
We weren’t. It was only going to get worse.
I thought I had the perfect software image (and BIOS) developed and deployed. However, that’s not what the field was telling us. Units kept failing. Sometimes a reboot would bring the unit back, usually it wouldn’t. When the unit was shipped back, however, it would work when tested.
Wow. Things just got weird.
The weirdness continued and I finally got to the point where I had to roll my sleeves up. I was lucky enough to find a very patient and helpful reseller in the field to stay on the phone with me for three hours while I collected data. This customer location, for some reason or another, could predictably bring down the ethernet controller with voice traffic on their network.
Let me elaborate on that for a second. When I say “bring down” an ethernet controller I mean BRING DOWN an ethernet controller. The system and ethernet interfaces would appear fine and then after a random amount of traffic the interface would report a hardware error (lost communication with PHY) and lose link. Literally the link lights on the switch and interface would go out. It was dead.
Nothing but a power cycle would bring it back. Attempting to reload the kernel module or reboot the machine would result in a PCI scan error. The interface was dead until the machine was physically powered down and powered back on. In many cases, for our customers, this meant a truck roll.
While debugging with this very patient reseller I started stopping the packet captures as soon as the interface dropped. Eventually I caught on to a pattern: the last packet out of the interface was always a 100 Trying provisional response, and it was always a specific length. Not only that, I ended up tracing this (Asterisk) response to a specific phone manufacturer’s INVITE.
I got off the phone with the reseller, grabbed some guys and presented my evidence. Even though it was late in the afternoon on a Friday, everyone did their part to scramble and put together a test configuration with our new hardware and phones from this manufacturer.
We sat there, in a conference room, and dialed as fast as our fingers could. Eventually we found that we could duplicate the issue! Not on every call, and not on every device, but every once in a while we could crash the ethernet controller. However, every once in a while we couldn’t at all. After a power cycle we’d try again and hit it. Either way, as anyone who’s tried to diagnose a technical issue knows the first step is duplicating the problem. We were finally there.
Believe me, it took a long time to get here. I know how the OSI stack works. I know how software is segmented. I know that the contents of a SIP packet shouldn’t do anything to an ethernet adapter. It just doesn’t make any sense.
Between packet captures on our device and packet captures from the mirror port on the switch we were finally able to isolate the problem packet. Turns out it was the received INVITE, not the transmitted 100 Trying! The mirror port capture never saw the 100 Trying hit the wire.
Now we needed to look at this INVITE. Maybe the userspace daemon processing the INVITE was the problem? Maybe it was the transmitted 100 Trying? One of my colleagues suggested we shutdown the SIP software and see if the issue persisted. No SIP software running, no transmitted 100 Trying.
First we needed a better way to transmit the problem packet. We isolated the INVITE transmitted from the phone and used tcpreplay to play it back on command. Sure enough it worked. Now, for the first time in months, we could shut down these ports on command with a single packet. This was significant progress and it was time to go home, which really meant it was time to set this up in the lab at home!
Before I go any further I need to give another shout out to an excellent open source piece of software I found. Ostinato turns you into a packet ninja. There’s literally no limit to what you can do with it. Without Ostinato I could have never gotten beyond this point.
With my packet Swiss army knife in hand I started poking and prodding. What I found was shocking.
It all starts with a strange SIP/SDP quirk. Take a look at this SDP:
v=0
o=- 20047 20047 IN IP4 10.41.22.248
s=SDP data
c=IN IP4 10.41.22.248
t=0 0
m=audio 11786 RTP/AVP 18 0 18 9 9 101
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:0 PCMU/8000
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:9 G722/8000
a=rtpmap:9 G722/8000
a=fmtp:101 0-15
a=rtpmap:101 telephone-event/8000
a=ptime:20
a=sendrecv
Wireshark picture:
Yes, I saw it right away too. The audio offer is duplicated and that’s a problem but again, what difference should that make to an Ethernet controller?!? Well, if nothing else it makes the ethernet frame larger...
But wait, there were plenty of successful ethernet frames in these packet captures. Some of them were smaller, some were larger. No problems with them. It was time to dig into the problem packet. After some more Ostinato-fu and plenty of power cycles I was able to isolate the problem pattern (with a problem frame).
Warning: we’re about to get into some hex.
The interface shutdown is triggered by a specific byte value at a specific offset. In this case the specific value was hex 32 at 0x47f. Hex 32 is an ASCII 2. Guess where the 2 was coming from?
a=ptime:20
All of our SDPs were identical (including ptime, obviously). All of the source and destination URIs were identical. The only difference was the Call-IDs, tags, and branches. Problem packets had just the right Call-ID, tags, and branches to cause the “2” in the ptime to line up with 0x47f.
BOOM! With the right Call-IDs, tags, and branches (or any random garbage) a “good packet” could turn into a “killer packet” as long as that ptime line ended up at the right address. Things just got weirder.
While generating packets I experimented with various hex values. As if this problem couldn’t get any weirder, it does. I found out that the behavior of the controller depended completely on the value of this specific address in the first received packet to match that address. It broke down to something like this:
Byte 0x47f = 31 HEX (1 ASCII) - No effect
Byte 0x47f = 32 HEX (2 ASCII) - Interface shutdown
Byte 0x47f = 33 HEX (3 ASCII) - Interface shutdown
Byte 0x47f = 34 HEX (4 ASCII) - Interface inoculation
Bad:
Good:
When I say “no effect” I mean it didn’t kill the interface but it didn’t inoculate the interface either (more on that later). When I say the interface shutdown, well, remember my description of this issue - the interface went down. Hard.
With even more testing I discovered this issue with every version of Linux I could find, FreeBSD, and even when the machine was powered up complaining about missing boot media! It’s in the hardware; the OS has nothing to do with it. Wow.
To make matters worse, using Ostinato I was able to craft various versions of this packet - an HTTP POST, ICMP echo-request, etc. Pretty much whatever I wanted. With a modified HTTP server configured to generate the data at byte value (based on headers, host, etc) you could easily configure an HTTP 200 response to contain the packet of death - and kill client machines behind firewalls!
I know I’ve been pointing out how weird this whole issue is. The inoculation part is by far the strangest. It turns out that if the first packet received contains any value (that I can find) other than 1, 2, or 3 the interface becomes immune from any death packets (where the value is 2 or 3). Also, valid ptime attributes are defined in
All of a sudden it’s become clear why this issue was so sporadic. I’m amazed I tracked it down at all. I’ve been working with networks for over 15 years and I’ve never seen anything like this. I doubt I’ll ever see anything like it again. At least I hope I don’t...
I was able to get in touch with two engineers at Intel and send them a demo unit to reproduce the issue. After working with them for a couple of weeks they determined there was an issue with the EEPROM on our 82574L controllers.
They were able to provide new EEPROM and a tool to write it out. Unfortunately we weren’t able to distribute this tool and it required unloading and reloading the e1000e kernel module, so it wouldn’t be preferred in our environment. Fortunately (with a little knowledge of the EEPROM layout) I was able to work up some bash scripting and ethtool magic to save the “fixed” eeprom values and write them out on affected systems. We now have a way to detect and fix these problematic units in the field. We’ve communicated with our vendor to make sure this fix is applied to units before they are shipped to us. What isn’t clear, however, is just how many other affected Intel ethernet controllers are out there.
I guess we’ll just have to see...